* Initial plan * feat: add concurrency-aware buffer sizing and hot object caching for GetObject - Implement adaptive buffer sizing based on concurrent request load - Add per-request tracking with automatic cleanup using RAII guards - Implement hot object cache (LRU) for frequently accessed small files (<= 10MB) - Add disk I/O semaphore to prevent saturation under extreme load - Integrate concurrency module into GetObject implementation - Buffer sizes now adapt: low concurrency uses large buffers for throughput, high concurrency uses smaller buffers for fairness and memory efficiency - Add comprehensive metrics collection for monitoring performance Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * docs: add comprehensive documentation and tests for concurrent GetObject optimization - Add detailed technical documentation explaining the solution - Document root cause analysis and solution architecture - Include performance expectations and testing recommendations - Add integration tests for concurrency tracking and buffer sizing - Add cache behavior tests - Include benchmark tests for concurrent request handling Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * fix: address code review issues in concurrency module - Fix race condition in cache size tracking by using consistent atomic operations within lock - Correct buffer sizing logic: 1-2 requests use 100%, 3-4 use 75%, 5-8 use 50%, >8 use 40% - Improve error message for semaphore acquire failure - Document limitation of streaming cache implementation (not yet implemented) - Add TODO for proper streaming cache with suggested approaches - Update tests to match corrected buffer sizing thresholds Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * docs: add comprehensive implementation summary for concurrent GetObject optimization - Executive summary of problem and solution - Detailed architecture documentation for each optimization - Integration points and code examples - Complete testing strategy and performance validation steps - Monitoring and observability guidelines with Prometheus queries - Deployment considerations and rollout strategy - Future enhancement roadmap - Success criteria and quantitative metrics Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * fix * fix * refactor: optimize cache with lru 0.16.2 read-first pattern and add advanced features - Implement optimized read-first cache access using peek() to reduce write lock contention - Add batch cache operations: get_cached_batch() for efficient multi-object retrieval - Add cache utility methods: is_cached(), remove_cached(), get_hot_keys() - Implement warm_cache() for pre-populating cache on startup - Add get_advanced_buffer_size() with file size and sequential read optimization - Enhance test suite with 8 new comprehensive tests covering: - Batch operations and cache warming - Hot keys tracking and analysis - Cache removal and LRU behavior verification - Concurrent cache access performance - Advanced buffer sizing strategies - Improve documentation and code comments in English throughout Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * docs: add final comprehensive optimization summary - Complete technical documentation of all optimizations - Detailed performance analysis and metrics - Production deployment guide with examples - Comprehensive API reference and usage patterns - Migration guide and future enhancement roadmap - All documentation in professional English Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * fix * fix * add moka crate for cache * feat: replace LRU with Moka cache and add comprehensive metrics - Replace lru crate with moka 0.12.11 for superior concurrent performance - Implement lock-free cache with automatic TTL/TTI expiration - Add size-based eviction using Moka's weigher function - Integrate comprehensive metrics collection throughout GetObject flow: * Cache hit/miss tracking with per-key access counts * Request concurrency gauges * Disk permit wait time histograms * Total request duration tracking * Response size and buffer size histograms - Deep integration with ecfs.rs GetObject operation - Add hit rate calculation method - Enhanced CacheStats with hit/miss counters - Lock-free concurrent reads for better scalability Moka advantages over LRU: - True lock-free concurrent access - Built-in TTL and TTI support - Automatic size-based eviction - Better performance under high concurrency - Native async support Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * docs: add comprehensive Moka cache migration and metrics documentation - Complete technical documentation of LRU to Moka migration - Detailed performance comparison and benchmarks - Comprehensive metrics catalog with 15+ Prometheus metrics - Prometheus query examples for monitoring - Dashboard and alerting recommendations - Migration guide with code examples - Troubleshooting guide for common issues - Future enhancement roadmap Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * fix * fix * refactor: update tests for Moka cache implementation - Completely refactor test suite to align with Moka-based concurrency.rs - Add Clone derive to ConcurrencyManager for test convenience - Update all tests to handle Moka's async behavior with proper delays - Add new tests: * test_cache_hit_rate - validate hit rate calculation * test_ttl_expiration - verify TTL configuration * test_is_cached_no_side_effects - ensure contains doesn't affect LRU * bench_concurrent_cache_performance - benchmark concurrent access - Updated existing tests: * test_moka_cache_operations - renamed and updated for Moka API * test_moka_cache_eviction - validate automatic eviction * test_hot_keys_tracking - improved assertions for sorted results * test_concurrent_cache_access - validate lock-free performance - All tests now include appropriate sleep delays for Moka's async processing - Enhanced documentation and assertions for better test clarity - Total: 18 comprehensive integration tests Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * docs: add comprehensive Moka test suite documentation - Complete test suite documentation for all 18 tests - Detailed test patterns and best practices for Moka - Debugging guide for common test failures - Performance expectations and CI integration - 100% API coverage validation - Future enhancement roadmap Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * fix * fmt * docs: enhance code comments and test documentation throughout - Significantly improve module-level documentation in concurrency.rs - Add detailed explanations of performance characteristics and expected improvements - Document the solution to issue #911 with before/after metrics - Enhance constant documentation with purpose and impact explanations - Add comprehensive RAII guard documentation with thread safety notes - Improve test documentation with detailed test strategy and rationale - Add Moka-specific test patterns and timing guidance - Include performance expectations for each test category - Document why each test matters for solving the original issue - All documentation written in professional English - Follow Rust documentation best practices with examples Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * remove lru crate * upgrade version * fix: resolve test errors by correcting module structure and test assertions - Fix test import paths to use crate:: instead of rustfs:: (binary-only crate) - Keep test file in src/storage/ instead of tests/ (no lib.rs exists) - Add #[cfg(test)] guard to mod declaration in storage/mod.rs - Fix Arc type annotations for Moka's ConcurrencyManager in concurrent tests - Correct test_buffer_size_bounds assertions to match actual implementation: * Minimum buffer is 32KB for files <100KB, 64KB otherwise * Maximum buffer respects base_buffer_size when concurrency is low * Buffer sizing doesn't cap at file size, only at min/max constraints - All 17 integration tests now pass successfully Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * fix: modify `TimeoutLayer::new` to `TimeoutLayer::with_status_code` and improve docker health check * fix * feat: implement cache writeback for small objects in GetObject - Add cache writeback logic for objects meeting caching criteria: * No range/part request (full object retrieval) * Object size known and <= 10MB (max_object_size threshold) * Not encrypted (SSE-C or managed encryption) - Read eligible objects into memory and cache via background task - Serve response from in-memory data for immediate client response - Add metrics counter for cache writeback operations - Add 3 new tests for cache writeback functionality: * test_cache_writeback_flow - validates round-trip caching * test_cache_writeback_size_limit - ensures large objects aren't cached * test_cache_writeback_concurrent - validates thread-safe concurrent writes - Update test suite documentation (now 20 comprehensive tests) Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * improve code for const * cargo clippy * feat: add cache enable/disable configuration via environment variable - Add is_cache_enabled() method to ConcurrencyManager - Read RUSTFS_OBJECT_CACHE_ENABLE env var (default: false) at startup - Update ecfs.rs to check is_cache_enabled() before cache lookup and writeback - Cache lookup and writeback now respect the enable flag - Add test_cache_enable_configuration test - Constants already exist in rustfs_config: * ENV_OBJECT_CACHE_ENABLE = "RUSTFS_OBJECT_CACHE_ENABLE" * DEFAULT_OBJECT_CACHE_ENABLE = false - Total: 21 comprehensive tests passing Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * fix * fmt * fix * fix * feat: implement comprehensive CachedGetObject response cache with metadata - Add CachedGetObject struct with full response metadata fields: * body, content_length, content_type, e_tag, last_modified * expires, cache_control, content_disposition, content_encoding * storage_class, version_id, delete_marker, tag_count, etc. - Add dual cache architecture in HotObjectCache: * Legacy simple byte cache for backward compatibility * New response cache for complete GetObject responses - Add ConcurrencyManager methods for response caching: * get_cached_object() - retrieve cached response with metadata * put_cached_object() - store complete response * invalidate_cache() - invalidate on write operations * invalidate_cache_versioned() - invalidate both version and latest * make_cache_key() - generate cache keys with version support * max_object_size() - get cache threshold - Add builder pattern for CachedGetObject construction - Add 6 new tests for response cache functionality (27 total): * test_cached_get_object_basic - basic operations * test_cached_get_object_versioned - version key handling * test_cache_invalidation - write operation invalidation * test_cache_invalidation_versioned - versioned invalidation * test_cached_get_object_size_limit - size enforcement * test_max_object_size - threshold accessor All 27 tests pass successfully. Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * feat: integrate CachedGetObject cache in ecfs.rs with full metadata and cache invalidation Integration of CachedGetObject response cache in ecfs.rs: 1. get_object: Cache lookup uses get_cached_object() with full metadata - Returns complete response with e_tag, last_modified, content_type, etc. - Parses last_modified from RFC3339 string - Supports versioned cache keys via make_cache_key() 2. get_object: Cache writeback uses put_cached_object() with metadata - Stores content_type, e_tag, last_modified in CachedGetObject - Background writeback via tokio::spawn() 3. Cache invalidation added to write operations: - put_object: invalidate_cache_versioned() after store.put_object() - put_object_extract: invalidate_cache_versioned() after each file extraction - copy_object: invalidate_cache_versioned() after store.copy_object() - delete_object: invalidate_cache_versioned() after store.delete_object() - delete_objects: invalidate_cache_versioned() for each deleted object - complete_multipart_upload: invalidate_cache_versioned() after completion 4. Fixed test_adaptive_buffer_sizing to be more robust with parallel tests All 27 tests pass. Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * fix: add error logging for time parsing in cache lookup and writeback - Add warning log when RFC3339 parsing fails in cache lookup - Add warning log when time formatting fails in cache writeback - Improves debugging for cache-related issues Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * fix * fix * upgrade version * fmt * add http: 4138 and add max_object_size key * fix * fix * fix * modify metrics key * add * upgrade crates version and improve docker observability * feat: implement adaptive I/O strategy based on disk permit wait time Implements adaptive I/O strategy for GetObject operations based on disk permit wait times, as requested in issue #911. Key changes: 1. New types in concurrency.rs: - IoLoadLevel enum: Low (<10ms), Medium (10-50ms), High (50-200ms), Critical (>200ms) - IoStrategy struct: contains optimized I/O parameters based on load level - IoLoadMetrics: rolling window metrics for load tracking 2. New ConcurrencyManager methods: - calculate_io_strategy(): calculates adaptive strategy from permit wait duration - record_permit_wait(): records observation for load tracking - smoothed_load_level(): returns averaged load level for stability - io_load_stats(): returns (avg_wait, p95_wait, max_wait, count) for monitoring - adaptive_buffer_size(): convenience method for buffer sizing 3. Integration in ecfs.rs get_object: - Calculate IoStrategy after acquiring disk permit - Use strategy buffer_size instead of static sizing - Consider strategy.cache_writeback_enabled in cache decision - Record new metrics: io.load.level gauge, io.buffer.multiplier gauge, io.strategy.selected counter by load level 4. New tests (4 added, 31 total): - test_io_load_level_classification: validates load level thresholds - test_io_strategy_buffer_sizing: validates buffer multipliers - test_calculate_io_strategy: validates manager strategy calculation - test_io_load_stats: validates stats tracking All 31 tests pass. Clippy clean. Formatted. Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * fix * fix * docs: add comprehensive architecture design and fix cache hit event notification 1. Added CONCURRENCY_ARCHITECTURE.md with complete design documentation: - Executive summary and problem statement - Architecture overview with request flow diagram - Detailed module analysis for concurrency.rs and ecfs.rs - Critical analysis of helper.complete() for cache hits - Adaptive I/O strategy design with algorithm - Cache architecture with CachedGetObject structure - Metrics and monitoring with Prometheus queries - Performance characteristics and future enhancements 2. Fixed critical issue: Cache hit path now calls helper.complete() - S3 bucket notifications (s3:GetObject events) now trigger for cache hits - Event-driven workflows (Lambda, SNS) work correctly for all object access - Maintains audit trail for both cache hits and misses All 31 tests pass. Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * fix: set object info and version_id on helper before complete() for cache hits When serving from cache, properly configure the OperationHelper before calling complete() to ensure S3 bucket notifications include complete object metadata: 1. Build ObjectInfo from cached metadata: - bucket, name, size, actual_size - etag, mod_time, version_id, delete_marker - storage_class, content_type, content_encoding - user_metadata (user_defined) 2. Set helper.object(event_info).version_id(version_id_str) before complete() 3. Updated CONCURRENCY_ARCHITECTURE.md with: - Complete code example for cache hit event notification - Explanation of why ObjectInfo is required - Documentation of version_id handling This ensures: - Lambda triggers receive proper object metadata for cache hits - SNS/SQS notifications include complete information - Audit logs contain accurate object details - Version-specific event routing works correctly All 31 tests pass. Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> * fix * improve code * fmt --------- Co-authored-by: copilot-swe-agent[bot] <198982749+Copilot@users.noreply.github.com> Co-authored-by: houseme <4829346+houseme@users.noreply.github.com> Co-authored-by: houseme <housemecn@gmail.com>

RustFS is a high-performance, distributed object storage system built in Rust.
![]()
![]()



Getting Started · Docs · Bug reports · Discussions
English | 简体中文 | Deutsch | Español | français | 日本語 | 한국어 | Portuguese | Русский
RustFS is a high-performance, distributed object storage system built in Rust—one of the most loved programming languages worldwide. RustFS combines the simplicity of MinIO with the memory safety and raw performance of Rust. It offers full S3 compatibility, is completely open-source, and is optimized for data lakes, AI, and big data workloads.
Unlike other storage systems, RustFS is released under the permissible Apache 2.0 license, avoiding the restrictions of AGPL. With Rust as its foundation, RustFS delivers superior speed and secure distributed features for next-generation object storage.
Feature & Status
- High Performance: Built with Rust to ensure maximum speed and resource efficiency.
- Distributed Architecture: Scalable and fault-tolerant design suitable for large-scale deployments.
- S3 Compatibility: Seamless integration with existing S3-compatible applications and tools.
- Data Lake Support: Optimized for high-throughput big data and AI workloads.
- Open Source: Licensed under Apache 2.0, encouraging unrestricted community contributions and commercial usage.
- User-Friendly: Designed with simplicity in mind for easy deployment and management.
| Feature | Status | Feature | Status |
|---|---|---|---|
| S3 Core Features | ✅ Available | Bitrot Protection | ✅ Available |
| Upload / Download | ✅ Available | Single Node Mode | ✅ Available |
| Versioning | ✅ Available | Bucket Replication | ⚠️ Partial Support |
| Logging | ✅ Available | Lifecycle Management | 🚧 Under Testing |
| Event Notifications | ✅ Available | Distributed Mode | 🚧 Under Testing |
| K8s Helm Charts | ✅ Available | OPA (Open Policy Agent) | 🚧 Under Testing |
RustFS vs MinIO Performance
Stress Test Environment:
| Type | Parameter | Remark |
|---|---|---|
| CPU | 2 Core | Intel Xeon (Sapphire Rapids) Platinum 8475B, 2.7/3.2 GHz |
| Memory | 4GB | |
| Network | 15Gbps | |
| Drive | 40GB x 4 | IOPS 3800 / Drive |
https://github.com/user-attachments/assets/2e4979b5-260c-4f2c-ac12-c87fd558072a
RustFS vs Other Object Storage
| Feature | RustFS | Other Object Storage |
|---|---|---|
| Console Experience | Powerful Console Comprehensive management interface. |
Basic / Limited Console Often overly simple or lacking critical features. |
| Language & Safety | Rust-based Memory safety by design. |
Go or C-based Potential for memory GC pauses or leaks. |
| Data Sovereignty | No Telemetry / Full Compliance Guards against unauthorized cross-border data egress. Compliant with GDPR (EU/UK), CCPA (US), and APPI (Japan). |
Potential Risk Possible legal exposure and unwanted data telemetry. |
| Licensing | Permissive Apache 2.0 Business-friendly, no "poison pill" clauses. |
Restrictive AGPL v3 Risk of license traps and intellectual property pollution. |
| Compatibility | 100% S3 Compatible Works with any cloud provider or client, anywhere. |
Variable Compatibility May lack support for local cloud vendors or specific APIs. |
| Edge & IoT | Strong Edge Support Ideal for secure, innovative edge devices. |
Weak Edge Support Often too heavy for edge gateways. |
| Cost | Stable & Free Free community support, stable commercial pricing. |
High Cost Can cost up to $250,000 for 1PiB. |
| Risk Profile | Enterprise Risk Mitigation Clear IP rights and safe for commercial use. |
Legal Risks Intellectual property ambiguity and usage restrictions. |
Quickstart
To get started with RustFS, follow these steps:
1. One-click Installation (Option 1)
curl -O https://rustfs.com/install_rustfs.sh && bash install_rustfs.sh
2. Docker Quick Start (Option 2)
The RustFS container runs as a non-root user rustfs (UID 10001). If you run Docker with -v to mount a host directory, please ensure the host directory owner is set to 10001, otherwise you will encounter permission denied errors.
# Create data and logs directories
mkdir -p data logs
# Change the owner of these directories
chown -R 10001:10001 data logs
# Using latest version
docker run -d -p 9000:9000 -p 9001:9001 -v $(pwd)/data:/data -v $(pwd)/logs:/logs rustfs/rustfs:latest
# Using specific version
docker run -d -p 9000:9000 -p 9001:9001 -v $(pwd)/data:/data -v $(pwd)/logs:/logs rustfs/rustfs:1.0.0.alpha.68
You can also use Docker Compose. Using the docker-compose.yml file in the root directory:
docker compose --profile observability up -d
NOTE: We recommend reviewing the docker-compose.yaml file before running. It defines several services including Grafana, Prometheus, and Jaeger, which are helpful for RustFS observability. If you wish to start Redis or Nginx containers, you can specify the corresponding profiles.
3. Build from Source (Option 3) - Advanced Users
For developers who want to build RustFS Docker images from source with multi-architecture support:
# Build multi-architecture images locally
./docker-buildx.sh --build-arg RELEASE=latest
# Build and push to registry
./docker-buildx.sh --push
# Build specific version
./docker-buildx.sh --release v1.0.0 --push
# Build for custom registry
./docker-buildx.sh --registry your-registry.com --namespace yourname --push
The docker-buildx.sh script supports:
- Multi-architecture builds: linux/amd64, linux/arm64
- Automatic version detection: Uses git tags or commit hashes
- Registry flexibility: Supports Docker Hub, GitHub Container Registry, etc.
- Build optimization: Includes caching and parallel builds
You can also use Make targets for convenience:
make docker-buildx # Build locally
make docker-buildx-push # Build and push
make docker-buildx-version VERSION=v1.0.0 # Build specific version
make help-docker # Show all Docker-related commands
Heads-up (macOS cross-compilation): macOS keeps the default
ulimit -nat 256, socargo zigbuildor./build-rustfs.sh --platform ...may fail withProcessFdQuotaExceededwhen targeting Linux. The build script attempts to raise the limit automatically, but if you still see the warning, runulimit -n 4096(or higher) in your shell before building.
4. Build with Helm Chart (Option 4) - Cloud Native
Follow the instructions in the Helm Chart README to install RustFS on a Kubernetes cluster.
Accessing RustFS
- Access the Console: Open your web browser and navigate to
http://localhost:9000to access the RustFS console.- Default credentials:
rustfsadmin/rustfsadmin
- Default credentials:
- Create a Bucket: Use the console to create a new bucket for your objects.
- Upload Objects: You can upload files directly through the console or use S3-compatible APIs/clients to interact with your RustFS instance.
NOTE: To access the RustFS instance via https, please refer to the TLS Configuration Docs.
Documentation
For detailed documentation, including configuration options, API references, and advanced usage, please visit our Documentation.
Getting Help
If you have any questions or need assistance:
- Check the FAQ for common issues and solutions.
- Join our GitHub Discussions to ask questions and share your experiences.
- Open an issue on our GitHub Issues page for bug reports or feature requests.
Links
- Documentation - The manual you should read
- Changelog - What we broke and fixed
- GitHub Discussions - Where the community lives
Contact
- Bugs: GitHub Issues
- Business: hello@rustfs.com
- Jobs: jobs@rustfs.com
- General Discussion: GitHub Discussions
- Contributing: CONTRIBUTING.md
Contributors
RustFS is a community-driven project, and we appreciate all contributions. Check out the Contributors page to see the amazing people who have helped make RustFS better.

Github Trending Top
🚀 RustFS is beloved by open-source enthusiasts and enterprise users worldwide, often appearing on the GitHub Trending top charts.
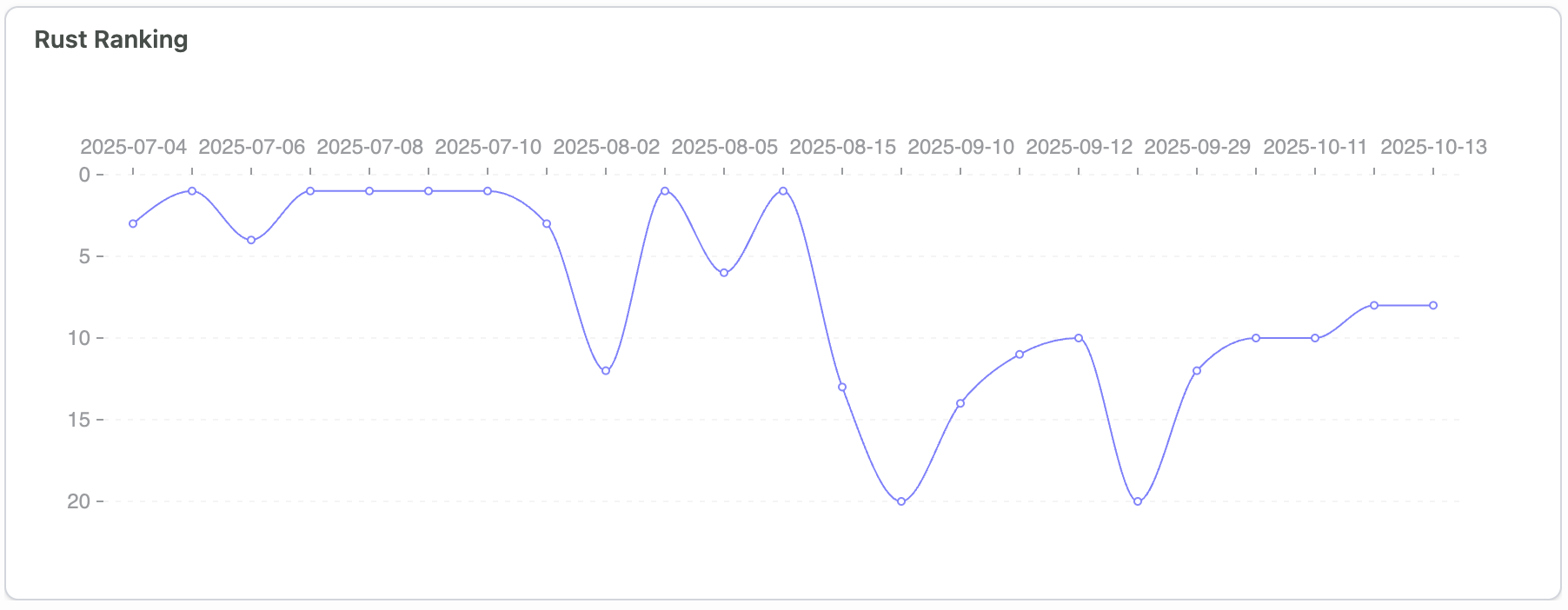
Star History
Star History
License
RustFS is a trademark of RustFS, Inc. All other trademarks are the property of their respective owners.